ELK日志服务使用-基本安装
说明
说在前面的话: elk对于没有接触的来说,并没有一般的服务那么容易安装和使用,不过也没有那么难,elk一般作为日志分析套装工具使用。logs由logstash输入,logstash通过配置文件对日志做过滤、匹配,就是用来分析日志的,输出到elasticsearch,所以他的配置需要和日志相匹配。elasticsearch可以看做是一个nosql数据库,是把logstash处理后的日志以日期方式存储起来。kibana从elastic里面获取日志数据,提供一个前端界面给日志做展示(和Grafana功能一样)。 logs →→ logstash →→ elasticsearch ←← kibana
下面是官方的说明: Logstash为存储、查询和分析日志提供强大的管道。使用Elasticsearch作为后端的数据存储和Kibana作为一个前端报告工具,Logstash充当主力。它包括内置输入,过滤器,编解码器和输出,让你的事半功倍。 一般应用的elk,版本还是有些差异的,所以使用前先确定版本
软件官方下载即可,下面为
版本号
OS:centos6.6 64bit java:jdk-7u79-linux-x64.rpm E:elasticsearch-1.7.3.tar.gz L:logstash-1.5.6-1.noarch.rpm K:kibana-4.1.2-linux-x64.tar.gz
注意:上面配置文件output中,elasticsearch在2.*新版本中host更改为了hosts,下面配置也一样,需要留意,推荐大家使用新版本的ELK
output { elasticsearch { hosts => localhost } }
否则报错信息如下:
Pipeline aborted due to error {:exception=>#<LogStash::ConfigurationError: The setting `host` in plugin `elasticsearch` is obsolete and is no longer available. Please use the 'hosts' setting instead. You can specify multiple entries separated by comma in 'host:port' format.
设置java环境
# rpm -ivh jdk-7u79-linux-x64.rpm
# /usr/java/jdk1.7.0_79/bin/java -version
# vim ~/.bashrc
export JAVA_HOME=/usr/java/jdk1.7.0_79
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
# . ~/.bashrc
# java -version
logstash的应用:
# mkdir /data/tar; cd /data/tar
# rpm -ivh logstash-1.5.6-1.noarch.rpm
# tree -L 1 /opt/logstash/
/opt/logstash/
├── bin
├── CHANGELOG.md
├── CONTRIBUTORS
├── Gemfile
├── Gemfile.jruby-1.9.lock
├── lib
├── LICENSE
├── NOTICE.TXT
└── vendor
cd /opt/logstash/
查看logstash的运行:
# ./bin/logstash -e 'input { stdin { } } output { stdout {} }' #logstash的基本输入输出处理
Logstash startup completed #启动完成
echo "this is test for logstash" #输入这一行,直接粘贴,不要手动输入,下面是logstash处理后的日志
2016-02-23T06:38:24.029Z localhost.localdomain this is test for logstash
查看elasticsearch的运行:
tar -xzf elasticsearch-1.7.3.tar.gz -C /opt/
ln -s /opt/elasticsearch-1.7.3/ /opt/elasticsearch
# /opt/elasticsearch/bin/elasticsearch & #默认配置启动elasticsearch
# curl -X GET http://localhost:9200 #elasticsearsh
{
"status" : 200,
"name" : "Mastermind of the UK",
"cluster_name" : "elasticsearch",
"version" : {
"number" : "1.7.3",
"build_hash" : "05d4530971ef0ea46d0f4fa6ee64dbc8df659682",
"build_timestamp" : "2015-10-15T09:14:17Z",
"build_snapshot" : false,
"lucene_version" : "4.10.4"
},
"tagline" : "You Know, for Search"
}
安装elasticsearch插件
elasticsearch 6的版本插件命令已更新,比如es 6.5.1安装 ik分词插件:
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analy
sis-ik/releases/download/v6.5.1/elasticsearch-analysis-ik-6.5.1.zip
es 2版本安装插件:
# cd /opt/elasticsearch
# ./bin/plugin -install lmenezes/elasticsearch-kopf
-> Installing lmenezes/elasticsearch-kopf...
Trying https://github.com/lmenezes/elasticsearch-kopf/archive/master.zip...
Downloading .............................................DONE
Installed lmenezes/elasticsearch-kopf into /opt/elasticsearch/plugins/kopf
可见插件的安装是下载zip包,再解压到plugins文件夹 下面测试这个kopf插件 kopf is a simple web administration tool for elasticsearch written in JavaScript + AngularJS + jQuery + Twitter bootstrap.https://github.com/lmenezes/elasticsearch-kopf
# ps aux|egrep "elastic|logstash"|grep -v grep|awk '{print $2}'|xargs kill -9
# ./bin/elasticsearch &
# /opt/logstash/bin/logstash -e 'input { stdin { } } output { elasticsearch { host => localhost } stdout { } }'
hello world #输入测试日志
2016-02-23T07:12:25.770Z localhost.localdomain hello world
# curl 'http://localhost:9200/_search?pretty' #会看到刚才输出一定格式log文件
{
"took" : 37,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"failed" : 0
},
"hits" : {
"total" : 3,
"max_score" : 1.0,
"hits" : [ {
"_index" : "logstash-2016.02.23",
"_type" : "logs",
"_id" : "AVMM-M6sQ5RLDkTmkGOV",
"_score" : 1.0,
"_source":{"message":"hello world","@version":"1","@timestamp":"2016-02-23T07:12:25.770Z","host":"localhost.localdomain"}
} ]
}
}
注意:上面配置文件output中,elasticsearch在2.*新版本中host更改为了hosts,下面配置也一样,需要留意
output { elasticsearch { hosts => localhost } }
# curl ‘http://localhost:9200/_plugin/kopf/’ #显示插件的页面,不过这个看不到东西 #在浏览器访问192.168.10.1:9200/_plugin/kopf/ 会打开如下界面,浏览保存在Elasticsearch中的数据,设置及映射
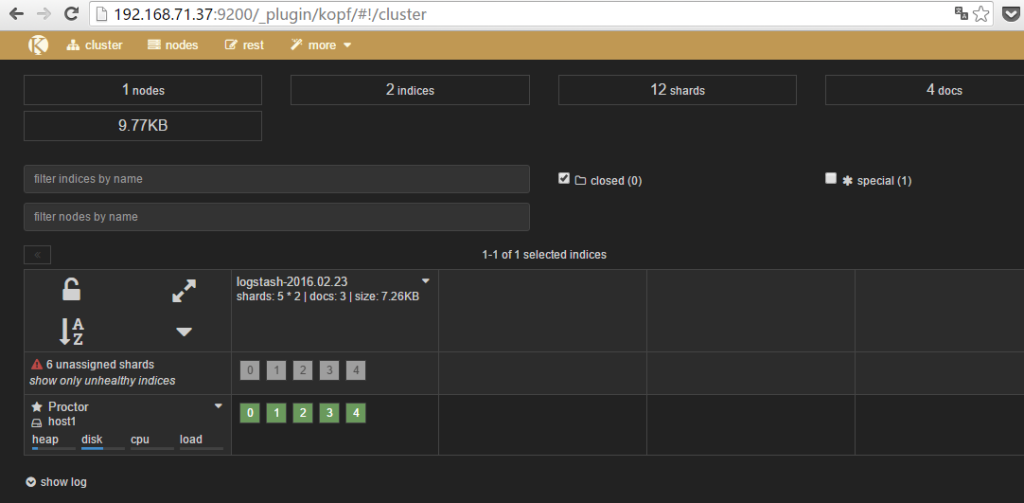
另,还有好多很不错的插件,都可以安装上去: es_head: 这个主要提供的是健康状态查询,当然标签页里也提供了简单的form给你提交API请求。es_head现在可以直接通过 elasticsearch/bin/plugin -install mobz/elasticsearch-head 安装,然后浏览器里直接输入http://$eshost:9200/_plugin/head/ 就可以看到cluster/node/index/shards的状态了 bigdesk: 这个主要提供的是节点的实时状态监控,包括jvm的情况,linux的情况,elasticsearch的情况。排查性能问题的时候很有用,现在也可以过 elasticsearch/bin/plugin -install lukas-vlcek/bigdesk 直接安装了。然后浏览器里直接输入 http://$eshost:9200/_plugin/bigdesk/ 就可以看到了。注意如果使用的 bulk_index 的话,如果选择的刷新间隔太长,indexing per second数据是不准的
Marvel: 这个插件是监控elasticsearch的状态和性能。包括集群的状态、实时处理的日志条数等
如果不能在线安装elasticsearch插件,则 bin/plugin install file:///path/to/plugin.zip 或者如下操作: 1.下载插件的zip包并解压,比如abc.zip 2.建立/opt/elasticsearch/plugins/abc文件夹 3.将解压后的abc文件夹下的文件copy到abc下 4.运行es 5.打开http://IP:9200/_plugin/abc/
查看安装了哪些插件 # /opt/elasticsearch/bin/plugin -l Installed plugins: – kopf
elk配置举例
下面是logstash和elasticsearch处理apache日志过程详细说明:
# /opt/elasticsearch/bin/elasticsearch &
# vim /opt/logstash/logstash-apache.conf #处理apache的error日志
input {
file {
path => "/var/log/httpd/error_log"
start_position => beginning
}
}
filter {
if [path] =~ "error" {
mutate { replace => { "type" => "apache_error" } }
grok {
match => { "message" => "%{COMBINEDAPACHELOG}" }
}
}
date {
match => [ "timestamp" , "dd/MMM/yyyy:HH:mm:ss Z" ]
}
}
output {
elasticsearch {
host => localhost
}
stdout { codec => rubydebug }
}
# /opt/logstash/bin/logstash -f /opt/logstash/logstash-apache.conf
稍等二十秒,如果没有输出,那么vim 这个日志,到最后面复制再粘贴一行,模拟写入日志
此时logstash会读apache的错误日志,在下面命令行会显示,http://IP:9200/_search?pretty浏览器页面也会看到
# vi logstash-apache.conf #处理apache的access日志
input {
file {
path => "/var/log/httpd/*_log"
}
}
filter {
if [path] =~ "access" {
mutate { replace => { type => "apache_access" } }
grok {
match => { "message" => "%{COMBINEDAPACHELOG}" }
}
date {
match => [ "timestamp" , "dd/MMM/yyyy:HH:mm:ss Z" ]
}
} else if [path] =~ "error" {
mutate { replace => { type => "apache_error" } }
} else {
mutate { replace => { type => "random_logs" } }
}
}
output {
elasticsearch { host => localhost }
stdout { codec => rubydebug }
}
# bin/logstash -f logstash-apache.conf
# /opt/logstash/bin/logstash -f /opt/logstash/logstash-apache.conf
通过上述操作,应该明白了logstash和elasticsearch的简单用法,下面是
配置文件的说明
事件的生命周期 Inputs,Outputs,Codecs,Filters构成了Logstash的核心配置项。Logstash通过建立一条事件处理的管道,从你的日志提取出数据保存到Elasticsearch中,为高效的查询数据提供基础。 Inputs input 及输入是指日志数据传输到Logstash中。其中常见的配置如下: file:从文件系统中读取一个文件,很像UNIX命令 “tail -0a” syslog:监听514端口,按照RFC3164标准解析日志数据 redis:从redis服务器读取数据,支持channel(发布订阅)和list模式。redis一般在Logstash消费集群中作为”broker”角色,保存events队列共Logstash消费。 Filters Fillters在Logstash处理链中担任中间处理组件。他们经常被组合起来实现一些特定的行为来,处理匹配特定规则的事件流。常见的filters如下: grok:解析无规则的文字并转化为有结构的格式。Grok是目前最好的方式来将无结构的数据转换为有结构可查询的数据。有120多种匹配规则,会有一种满足你的需要。 mutate:mutate filter 允许改变输入的文档,你可以从命名,删除,移动或者修改字段在处理事件的过程中。 drop:丢弃一部分events不进行处理,例如:debug events。 clone:拷贝event,这个过程中也可以添加或移除字段。 geoip:添加地理信息(为前台kibana图形化展示使用) Outputs outputs是logstash处理管道的最末端组件。一个event可以在处理过程中经过多重输出,但是一旦所有的outputs都执行结束,这个event也就完成生命周期。一些常用的outputs包括: elasticsearch:如果你计划将高效的保存数据,并且能够方便和简单的进行查询 file:将event数据保存到文件中 graphite:将event数据发送到图形化组件中,一个很流行的开源存储图形化展示的组件。http://graphite.wikidot.com/ statsd:statsd是一个统计服务,比如技术和时间统计,通过udp通讯,聚合一个或者多个后台服务,如果你已经开始使用statsd,该选项对你应该很有用 Codecs codecs 是基于数据流的过滤器,它可以作为input,output的一部分配置。Codecs可以帮助你轻松的分割发送过来已经被序列化的数据。流行的codecs包括 json,msgpack,plain(text)。 json:使用json格式对数据进行编码/解码 multiline:将汇多个事件中数据汇总为一个单一的行。比如:java异常信息和堆栈信息 获取完整的配置信息,请参考 Logstash文档中 “plugin configuration”部分
kibana
当运行kibana的时候,会在elasticsearch中新建.kibana的索引index,如果你的elasticsearch之前已经在跑其他的业务,请手动建立.kibana的index。在电脑打开 http://IP:5601/
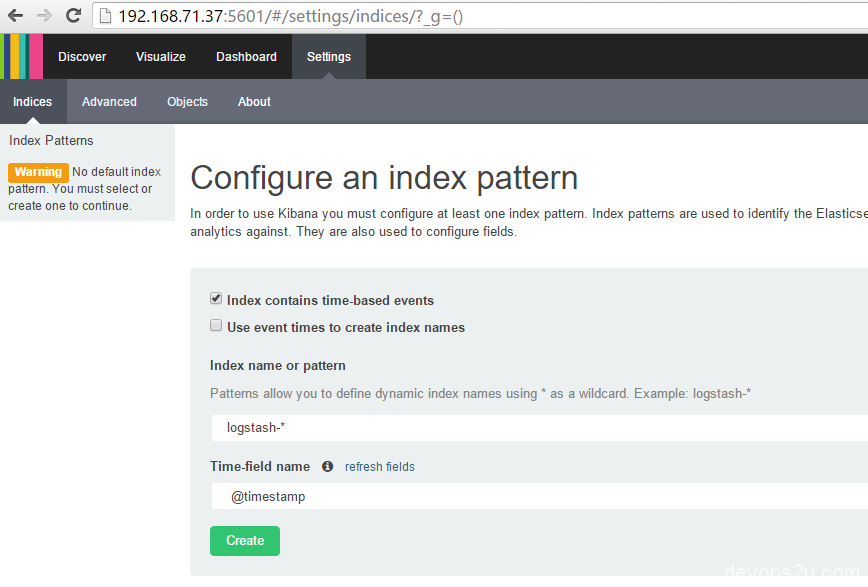
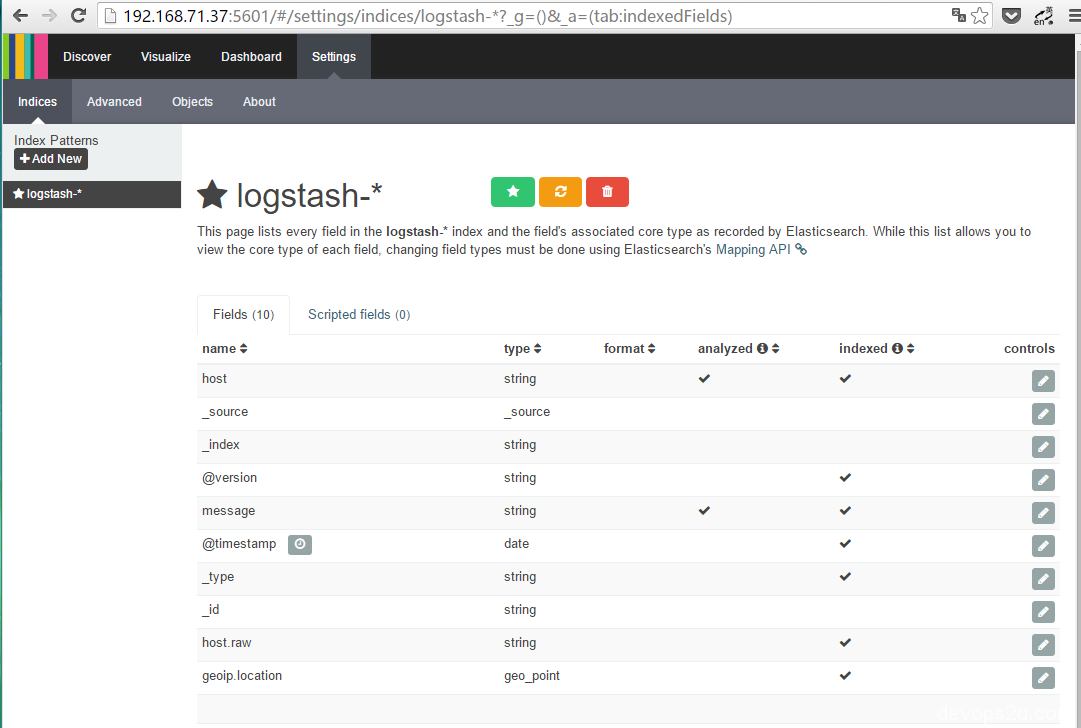
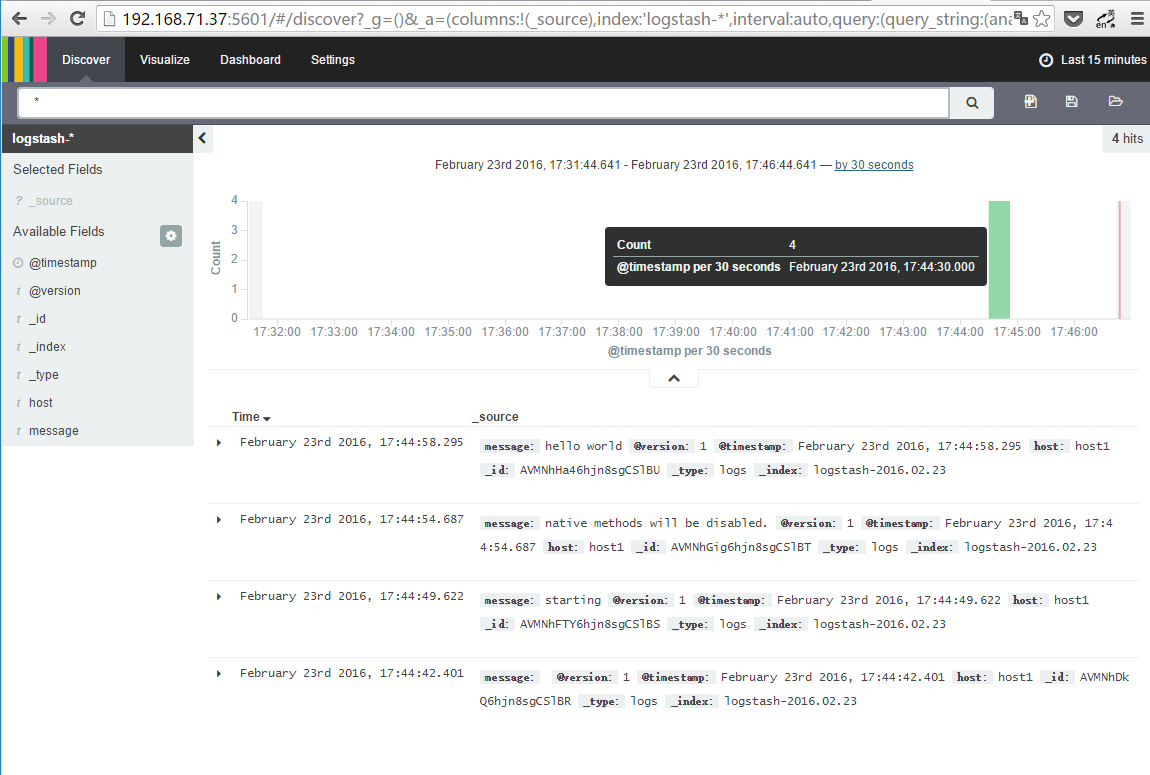
另,kibana有经常退出的情况,这里用一个shell脚本
# less /etc/init.d/kibana
#!/bin/bash
### BEGIN INIT INFO
# Provides: kibana
# Default-Start: 2 3 4 5
# Default-Stop: 0 1 6
# Short-Description: Runs kibana daemon
# Description: Runs the kibana daemon as a non-root user
### END INIT INFO
# Process name
NAME=kibana
DESC="Kibana4"
PROG="/etc/init.d/kibana"
# Source function library.
. /etc/rc.d/init.d/functions
# Configure location of Kibana bin
KIBANA_BIN=/opt/kibana/bin
# PID Info
PID_FOLDER=/var/run/kibana/
PID_FILE=/var/run/kibana/$NAME.pid
LOCK_FILE=/var/lock/subsys/$NAME
PATH=/bin:/usr/bin:/sbin:/usr/sbin:$KIBANA_BIN
DAEMON=$KIBANA_BIN/$NAME
# Configure User to run daemon process
DAEMON_USER=root
# Configure logging location
KIBANA_LOG=/var/log/kibana.log
# Begin Script
RETVAL=0
if [ `id -u` -ne 0 ]; then
echo "You need root privileges to run this script"
exit 1
fi
start() {
echo -n "Starting $DESC : "
pid=`pidofproc -p $PID_FILE kibana`
if [ -n "$pid" ] ; then
echo "Already running."
exit 0
else
# Start Daemon
if [ ! -d "$PID_FOLDER" ] ; then
mkdir $PID_FOLDER
fi
daemon --user=$DAEMON_USER --pidfile=$PID_FILE $DAEMON 1>"$KIBANA_LOG" 2>&1 &
sleep 2
pidofproc node > $PID_FILE
RETVAL=$?
[[ $? -eq 0 ]] && success || failure
echo
[ $RETVAL = 0 ] && touch $LOCK_FILE
return $RETVAL
fi
}
reload()
{
echo "Reload command is not implemented for this service."
return $RETVAL
}
stop() {
echo -n "Stopping $DESC : "
killproc -p $PID_FILE $DAEMON
RETVAL=$?
echo
[ $RETVAL = 0 ] && rm -f $PID_FILE $LOCK_FILE
}
case "$1" in
start)
start
;;
stop)
stop
;;
status)
status -p $PID_FILE $DAEMON
RETVAL=$?
;;
restart)
stop
start
;;
reload)
reload
;;
*)
# Invalid Arguments, print the following message.
echo "Usage: $0 {start|stop|status|restart}" >&2
exit 2
;;
esac
# chmod +x /etc/init.d/kibana
启动的话执行 service kibana restart即可。
问:为什么elk安装这么麻烦,有没有简单的?
答:这篇文章写的过程对于安装来说是多余了些,主要是让大家明白logstash和elasticsearch一般的运行,这点明白了以后操作就容易自己解决问题。
本文是在本地虚拟机下操作的,对于elk配置文件没有任何的更改,下一篇会写配置文件的意思。
ELK的资料 https://www.elastic.co/guide/index.html elk官网文档 https://www.gitbook.com/book/chenryn/kibana-guide-cn/details 三斗室的ELKstack 中文指南比较不错,ELKstack权威指南作者
http://www.rsyslog.com/tag/elasticsearch/ rsyslog官网提供的优秀文档,敬仰链接中写文章的大师
https://ianunruh.com/2014/05/monitor-everything.html
http://logstash-best-practice.readthedocs.org/zh_CN/latest/README/
2016年02月23日 于 linux工匠 发表